星空·综合体育官网入口 AI机器学习实战の电磁智能车篇
AI机器学习实战の电磁智能车篇
卓大大公布关于RT106x电磁智能车AI算法的推文之后,该算法被选作2020年智能车竞赛项目,引起师生们的广泛讨论。许多同学渴望在各自的赛道体验AI的神奇,却因缺少相关资料和开发工具而感到困惑。
我们在此说明在RT106x车辆上应用人工智能的具体步骤,同时呈现一个基础的电磁导航神经网络范例,期待以此引发同学们的深入思考,推动人工智能在电磁智能车领域的广泛应用。
硬件条件
无需多言,必须配备一辆电磁智能车,还需要无线传输设备来收集训练信息,感谢逐飞科技提供友情支持。
这张图片展示的是我们运用中的汽车模型,红色边界框中车身包含的七个电感元件,是人工智能运算里电磁车辆行进路径控制的信号来源。

蓝色框里的电感用于采集训练数据时的路径指引,AI算法并不调用它(模型部署完成之后可以移除)。
软件环境
Python:3.7.3
Keras:2.2.4
TensorFlow:1.13.1
该模型旨在依据车辆框架的电感数值,计算出针对微型车转向装置的操作指令,属于一种典型的预测任务。
我们训练了简易的Baseline模型,结构如下:
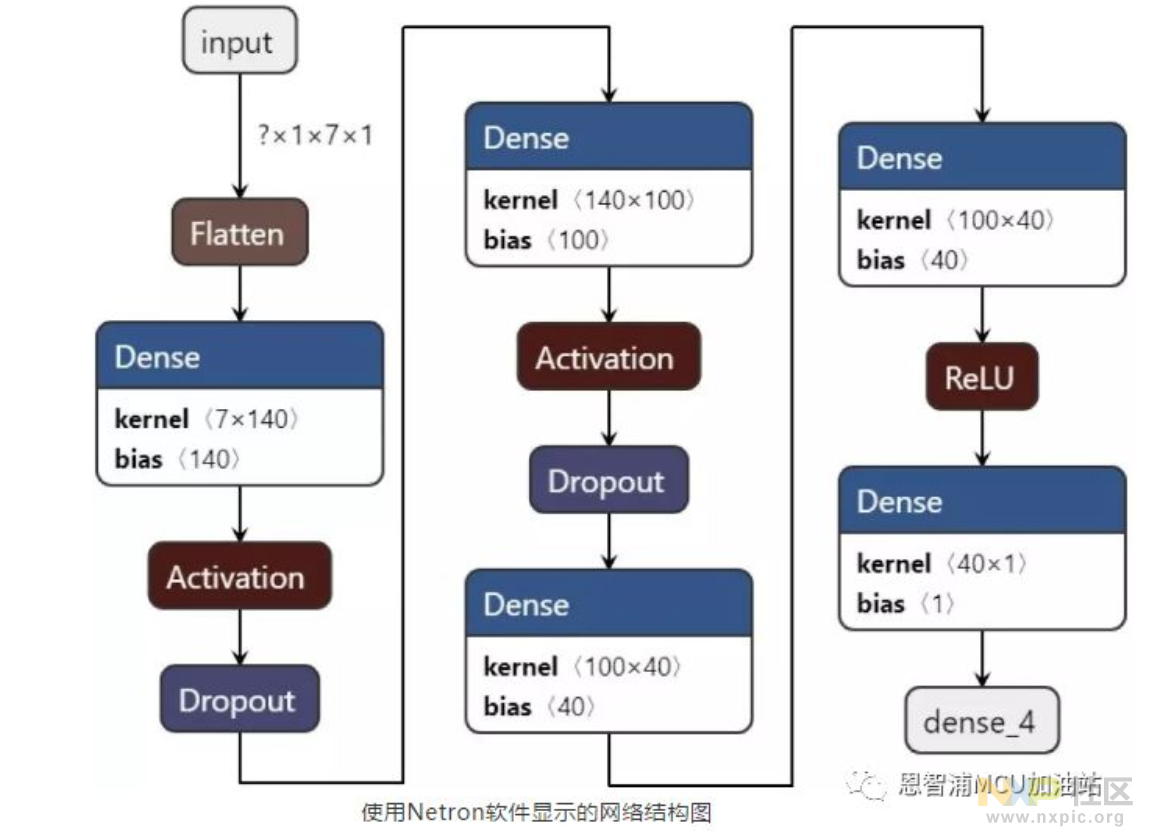
如图所见,该模型仅运用了全连接单元,即Dense算子,在某些资料中也称作多层感知机,仅取最近一次记录的七个电感数值,参数总数达十九万三千零一,内存占用轻微,处理效率很高,即便在RT1060平台上以十六位精度运行也毫无负担
但是,各位同学不要认为模型制作完成就结束了,不要以为有了人工智能模型就可以忽略传统算法中参数调整的艰辛。我可以明确地告诉大家,真正的挑战才正要来临。
采集数据,训练模型
数据的采集和处理
人们普遍认识到训练数据在机器学习中的核心地位,缺少完善的数据AI模型如同空中楼阁,毫无价值可言。对于模型来说,训练数据好比兵源充足,越多越好,但必须注意避免掺杂错误信息,否则会导致系统失灵,问题难以追踪。为了准备训练数据,编辑们耗费了大量心血,牺牲了许多思考时间。
我们采集训练数据的方式是:车辆采用传统路径规划技术行驶,由车头感应器进行导航,即时获取车身感应信息,以及转向参数,这些数据通过无线传输装置传送到电脑,电脑上的通信软件将信息记录为文本文件。
怎么把文本格式的数据转换成训练数据呢?这就需要用到功能强大的Python了星空·综合体育官网入口,先在程序中导入文本文档,将那七组AD数据分别设置为x_train和x_test,而对应的转向信号pwm则对应为y_train和y_test,接着把它们存为numpy格式的数组文件,这样训练程序就能直接读取,最好创建四个文件,分别是x_train.npy、x_test.npy、y_train.npy和y_test.npy,同时务必确保数据规格满足模型要求,并且数值区间要调整到-128到127之间,这是制作测试数据时的必要步骤。
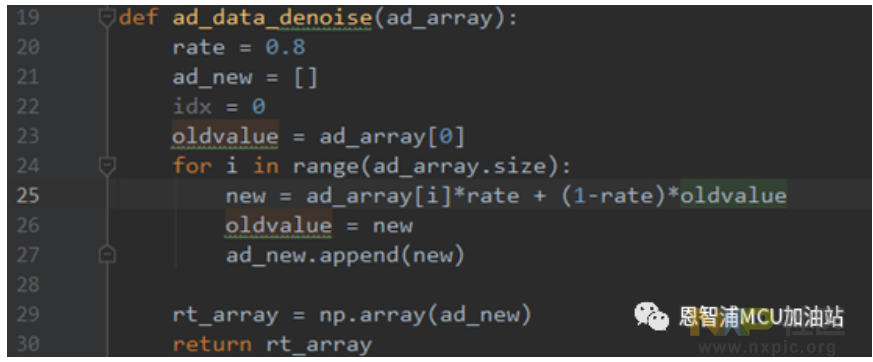
数据转换期间,必须对AD值实施基础过滤处理,下面提供的滤波方法可供参考。
模型训练
训练脚本首先加载训练数据中的numpy文件,接着将数据值域归一化处理,使其介于负一与正一之间,数据类型为浮点数,然后改变数据矩阵的维度,使其符合模型输入所需的参数规格。
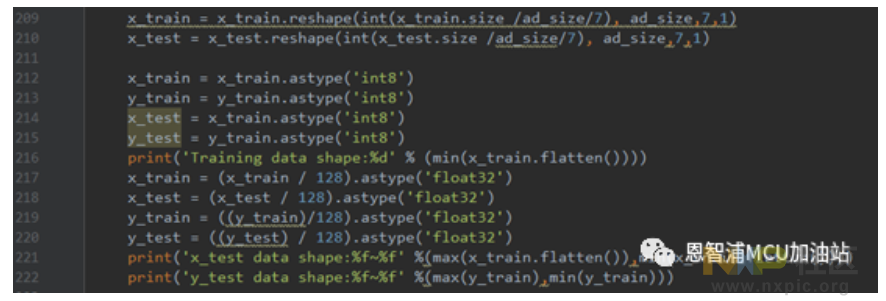
将源代码中关联的若干行分作独立段落,每段附带中文说明,例如调整形状的,转换数据类型的
模型函数:
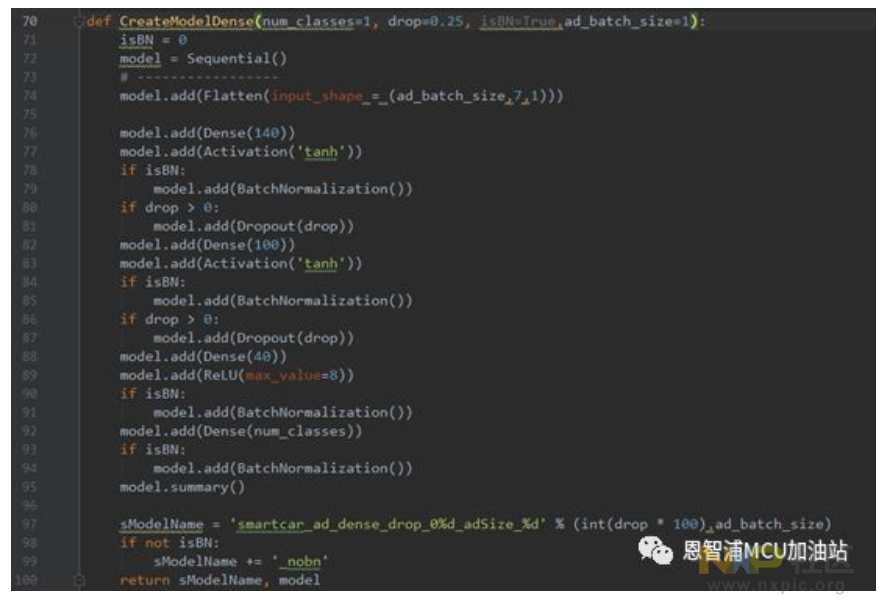
模型训练部分代码(添加少量关键中文注释):
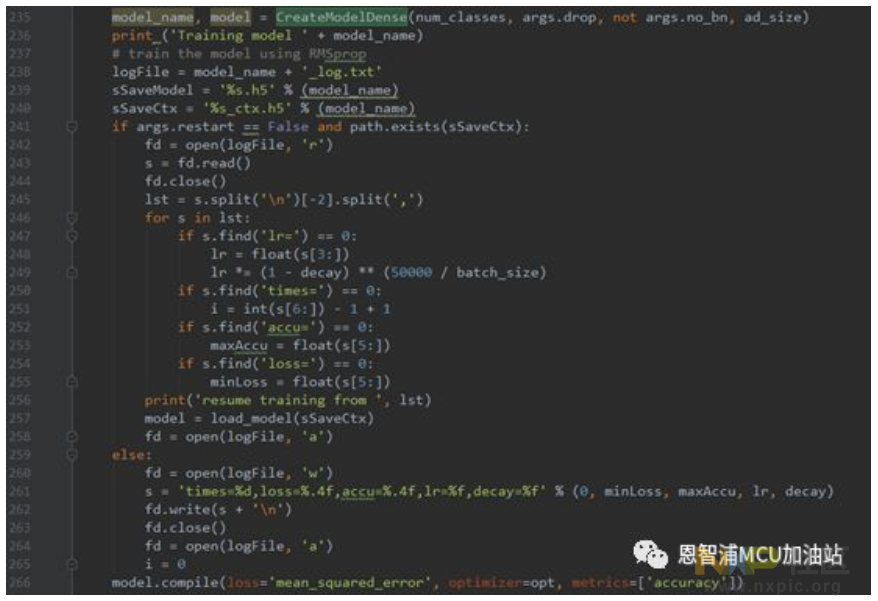
这个位置存放了临时文件xxx_ctx.h5,目的是为了在训练过程突然中断的情况下,能够重新开始时继续之前的进度。
优化方法选用了RMSprop,衡量误差则采用均方误差。
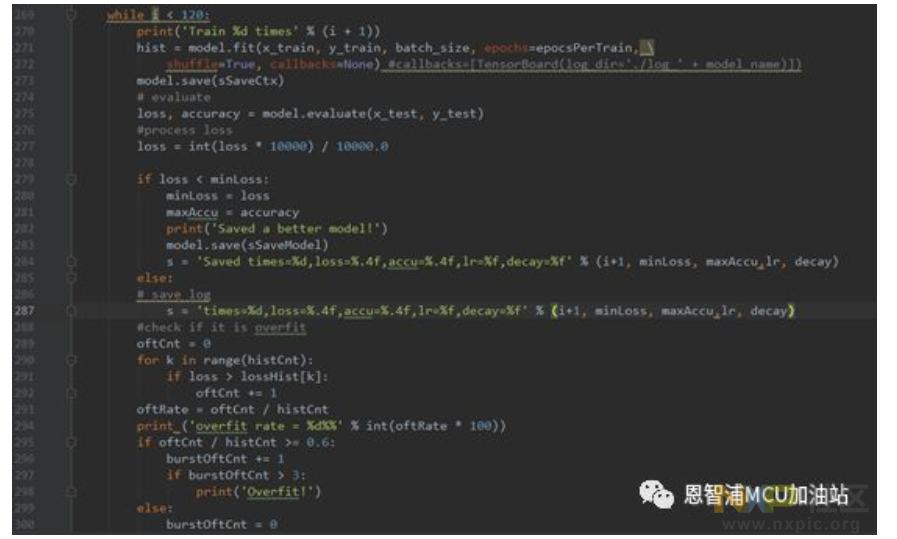
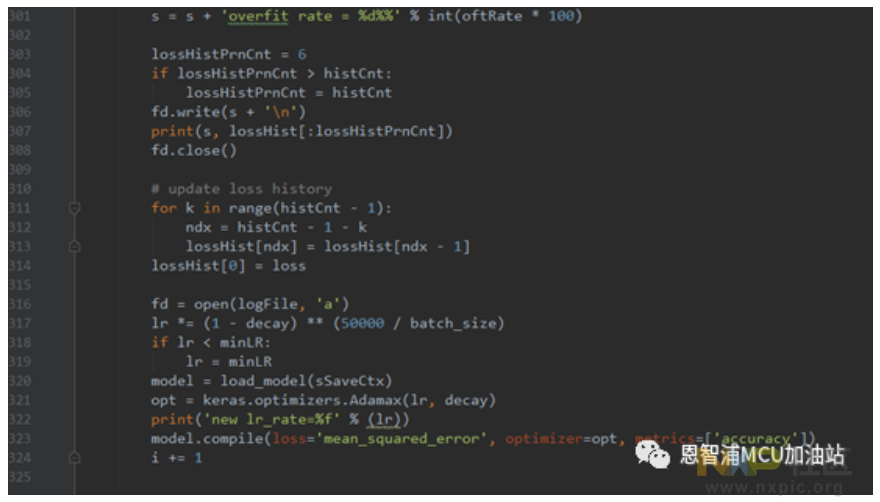
训练期间偏差快速减小,减小的速率逐渐放缓,经过20次迭代后准确度便达到了理想水平。现在呈现的是完成120次训练的成果:损失值为0.0044。

各位读者看到此处,脑海中是否浮现出自动驾驶车辆驰骋的景象了,而且急切地想要将调试完成的方案安装到载具之中了?
不不不,总被现实教训的笔者要说明这远远不够。理由很简单,模型出现了过度拟合。AI系统在运作时会伴随偏差,这些偏差最终会引发偏差,具体有哪些偏差呢
模型运算过程中产生的偏差,逻辑回归方法带来的偏差,不论训练多少次都必然会有某种程度的偏差
2.训练数据采集时的误差,前置电感和车身电感距离上的误差
累积误差,第一种和第二种误差会造成小车偏离预定路线,偏差会随之扩大。当误差累积到训练数据中未曾记录的程度时,模型将束手无策,这是小车跑偏的根本原因。这个道理虽然浅显,但作者实际经历了很长时间才领悟到。
查明问题关键后,就能有的放矢:务必让学习资料中包含车辆重归正常行驶的各种情况。简而言之,就是要加入车辆从偏离路线状态调整回正确轨迹的修正信息,我们采用两种途径来获取修正信息。
第1种方法:将小车电机设置为手动操控状态,但需确保转向控制与数据采集功能正常启用。将小车放置于偏离轨道的位置,用手直接推动小车,小车本来的控制程序会调整方向使其回到原路上。在此过程中,需要捕捉即时信息并加以记录。具体操作请参考相关视频资料
第二种方法:采用传统算法操控小车时,施加偶然扰动,导致车辆暂时偏离路线,并使控制程序暂停运行,车辆会脱离轨道,在程序重新启动后迅速调整方向,并即时记录修正过程,具体演示请参考相关视频
总结一下,数据分三部分:
经典算法导航的正常数据。
手动偏移的纠正数据。
经典算法随机干扰的纠正数据。
将三个数据整合为一个训练数据集,需要留意第2种方法存在引入错误数据的可能,例如小车严重偏离赛道,手动调整时小车与赛道平面夹角过大,或者与水平面距离过远,这些情况在实际操作中必须谨慎处理。因为机器学习模型具有不可解释性,错误数据或不恰当的数据会导致模型表现出不可预测的行为,因此整个流程可能需要反复试验和不断优化。
模型部署
反复训练之后,我们获得了最终的模型文件smartcar.h5。
部署到车辆上需要借助“NNCU”这个关键设备。NNCU模型转换器可以从网络存储空间获取,那里有一个资源包,里面包含nnCU工具、教学影片、使用指南,以及MCU+AI的演示文稿。
借助工具将模型转为C语言源码文件,此举便于将其添加至既有项目体系,务必留意须引入部分必需的函数库与实现库,可参照效率评估项目(nncie_stub.uvproj)来执行
从网盘里取得nncu_test_nighty.7z压缩包并解压,接着执行nncu_vbgui.bat文件,然后挑选模型文件,具体设置如下:
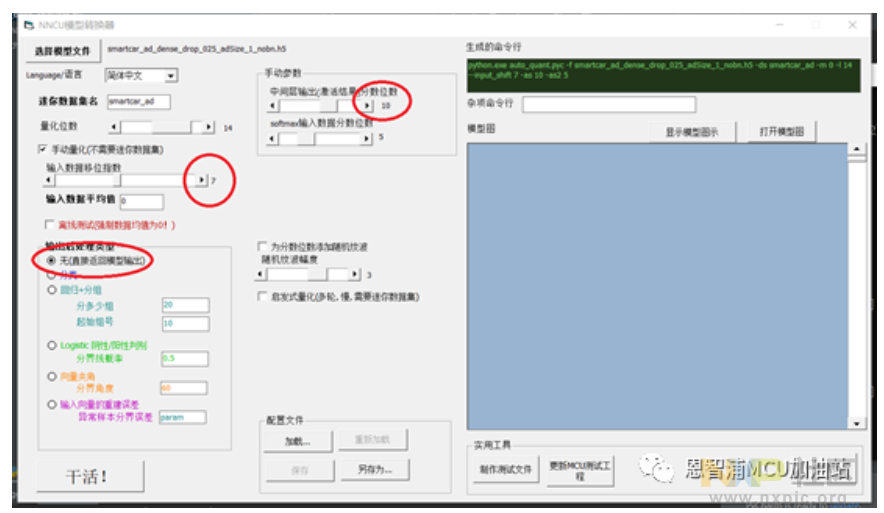
这个模型采用14位进行数值表示,而针对NNCU软件,9到16位的数据范围均以16位整数形式来处理。
16位量化与8位量化对比,需要付出少量推理阶段开销,并使模型数据容量翻倍,才能获得几乎不降低的准确度。
此处另有一项关键性提示:即便选用16位整数进行表述,实际操作中仅需应用其中的9至15位即可(未被应用的位会自动完成符号扩展),此举旨在预防模型运算过程中发生乘累加的溢出情形。
输入数据的位移指数为7位,表明有7个二进制位用来表示小数部分。回想之前提到,测试集和训练集的数据取值范围在-128到+127之间,而模型在训练时处理的数据范围是-1到+1。因此,量化后的数据实际上被放大了128倍,这对应着7个二进制的小数位。
我们接着讨论“输出加工方式”。因为模型用于预测,后续加工工作需要用户自行完成,无需由执行引擎进行加工。
中间层和输出层的数值精度:模型结果介于负一和正一之间,十位分辨率已经相当充分,因此用十位来表示分数,占用了量化总位数中十四位的十位。也可以尝试其他位数,例如九到十三位,通常效果变化非常微小。
按下“执行”,会弹出一个用于后台转换指令的对话框,过一会儿,在nncu_pc文件夹里会出现model1.nncu.c——这个是模型运行所需要的文件。接下来要了解的是如何操作,还有模型在经过量化处理之后,运行效率如何。
NNCU软件中设有名为“test_mcu”的测试项目,同学们借助该项目能够评估量化模型的实际表现,同时也能以此为基础开展模型迁移任务。详细步骤,可查阅相关视频的结尾段落,或者阅读微信公众号文章《在MCU上实现AI深度学习,你想知道的都在这儿》获取更多信息。
评估运作效果,须先准备测试资料库。以ad_test_dat.npy为数据源,将模型运算值同pwm_test_label.npy数据对比的偏差平方取平均值,以此来衡量量化模型的运作水平。
将训练数据与测试数据转移到名为“datasets\smartcar_ad”的文件夹内,具体命名方式如下:
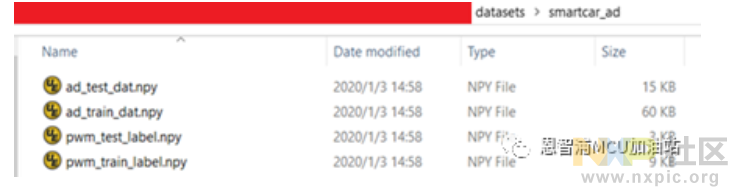
在工具右下角找到“生成测试数据”的选项并点击。从迷你数据集里挑选smartcar_ad。接着按“开始处理”。会在nncu_pc这个文件夹里创建一个名为smartcar_ad.nctv.c的测试文档。
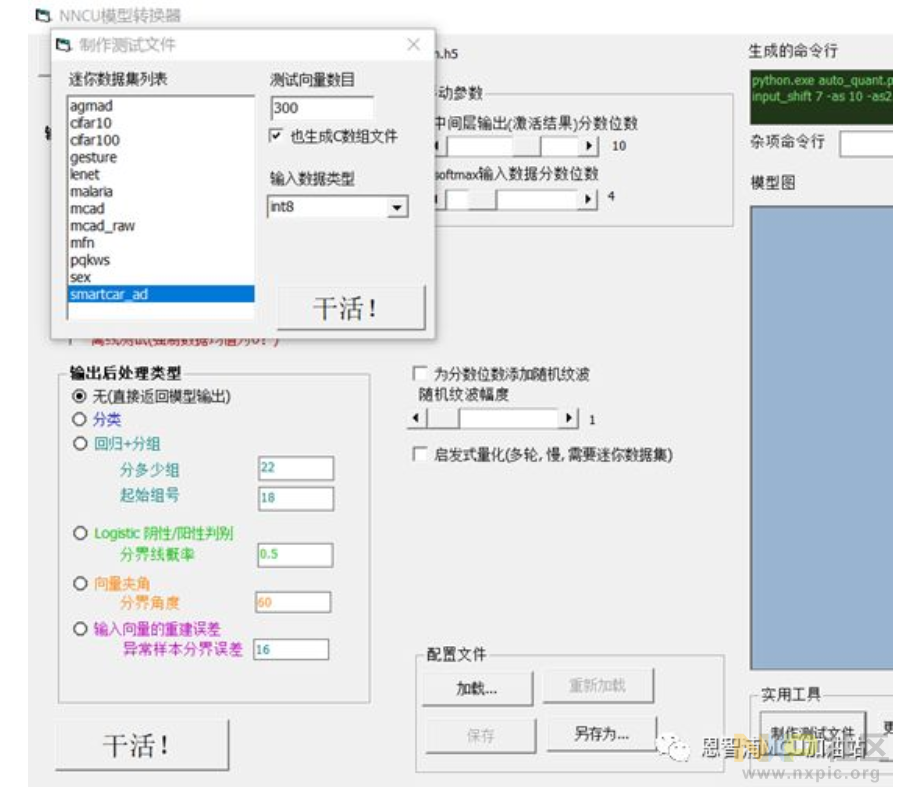
接下来要检测模型的运作情况,可以参考指导影片《nncu_使用入门.mp4》。将model1.nncu.c和smartcar_ad.nctv.c复制到文件夹test_mcu\boards\evkmimxrt1060\demo_apps\nncie_stub里,原有文件model.nncu.c和tv.nctv.c将被替换掉。
打开工程mdk\ncie_stub.uvprojx文件,接着在helo_world.c文件里找到测试函数CIETest,然后对模型计算测试集星空体育平台官网入口,并得到平均差值,平均差值数值越小,说明模型在测试集上的适配程度越好。但是,在不存在累积偏差的情况下,实际上需要补充大量能够回归正常的数据,否则即便误差值很小,也无法确保实际成效,这仅仅意味着模型出现了过度拟合,导致在测试数据上表现优异。
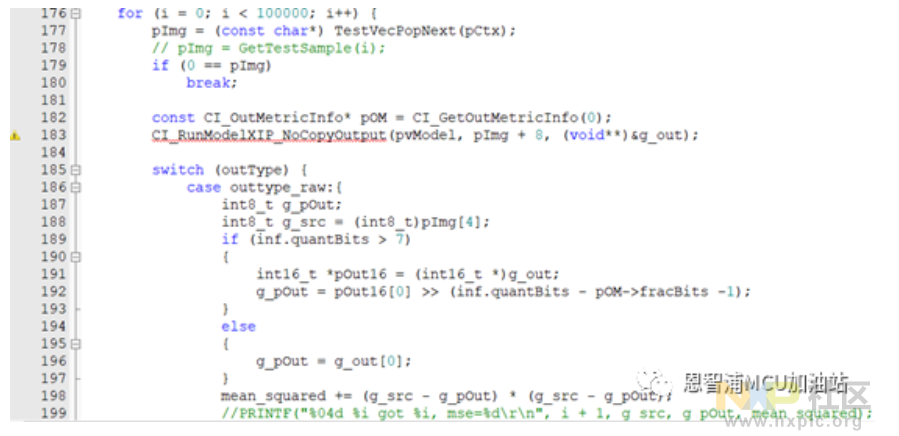
CI执行模型XIP指令,不复制输出,参数为模型指针,图像数据偏移8位,输出地址引用传给g_out
是模型执行的函数调用,用法如下:
pvModel代表模型数据,该数据在model1.nncu.c文件中定义,里面存放着模型的相关信息以及参数
pImg + 8 – x_text 也就是7个AD数值
g_out是模型的输出缓存,依据设定以16位格式呈现,其中包含小数部分信息。必须进行位移处理,以便转换成-128至+127的数值区间,然后才能传输给舵机。
编译项目,借助JLink与硬件相连,同时启动串口软件,用以获取串口反馈的调试数据。切换至调试状态,项目会优先在sram中运行代码,静候测试代码完成操作。测试程序运行完毕,串口便会通报操作成效:具体表现为平均误差值,以及平均操作时长。
该小编培养的模型在6000次运算中的平均误差为16,单次运算耗时极短,具体为0.187毫秒,折合1.87微秒。
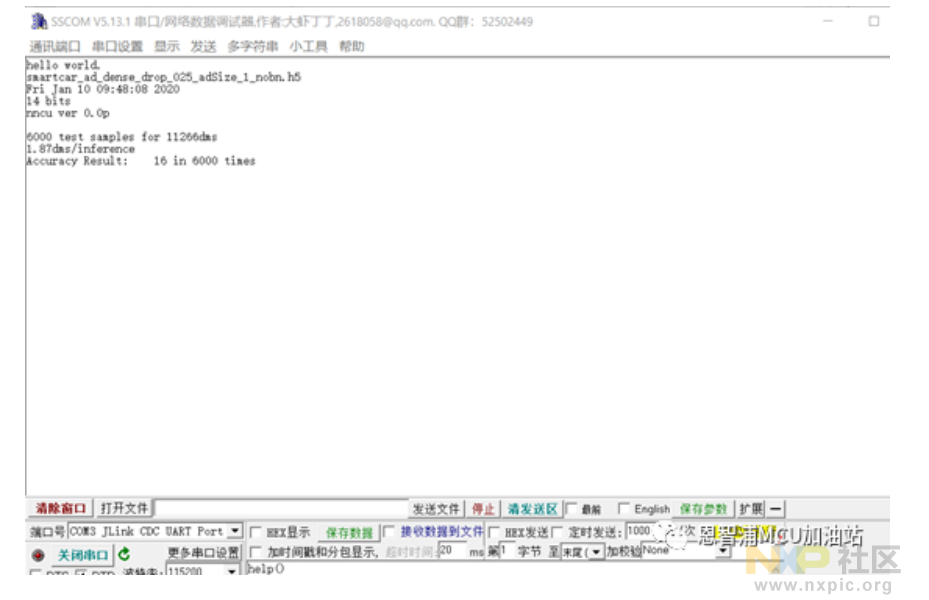
模拟测试表明模型表现达到标准,接下来需要将相关程序段合并到电磁车系统中,首先整合nncie库nncie_imxrt10x0.lib,model.nncu.c,还要把nncu_mcu\cmsis_nn\Source目录下的CMSIS_NN相关程序(以测试工程为参考)加入其中,其次要整合模型的调用方式

model1数组代表模型信息,ad_array包含七个电感数值,若为十二位数据需调整至八位,pwm为模型计算得出的转向数值,其范围介于负一百二十八至正一百二十七之间。制作训练数据时,为了便于计算过程,我们将转向值的区间从原始范围-420到420缩小为-128到127,因此,在操控舵机时,必须将计算出的转向数值调整到-420到+420之间
现在朋友们可以在跑道上测试模型的实际效果了,也许初次尝试不会顺利,要更有恒心处理训练资料,不断地重新训练,反复地调整优化。
这是小编训练的模型的实际运行情况(摘除了前置采集装置)
该流程涵盖了人工智能机器学习在电磁智能车上的完整部署,能够证明机器学习技术应用于电磁智能车的实际操作性。
这个阶段碰到了不少困难,核心在于加工和研究训练资料,反复调整才产生一个尚可信赖的方案。
当然还存在一些有待改进地方:
小车当前维持恒定速度,速率并无波动星空体育官方网站,如何构思更优化的方案来整合速率变量?
获取数据的方法是否能够改进,可以借助电磁轨道的模拟,运用公式手段,推演出训练数据?
如何增加更多种类的赛道元素,例如交通路线的规划,信号灯的设置,以及各种障碍物的布置等等。
同学们还能构思出许多新颖建议,参赛者与大家都可以积极思考,促使人工智能学习的潜能得到充分展现。
此处另有一篇关联文献可供借鉴:关于i.MX RT电磁型智能车辆人工智能方法的部分探讨
作者为张岩,文章发布于恩智浦MCU加油站平台,内容详实专业,值得参考阅读。
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论